
In our evaluation, we focus on two of the most representative Multimodal Large Language Models (MLLMs) currently available: GPT4-V and Gemini Pro. We tested these models under three distinct settings: zero-shot, few-shot, and text-only. In the zero-shot setting, the models are provided with the problem without any prior examples. The few-shot setting involves giving the models a small number of example problems and solutions to ‘learn’ from before attempting the new problems. We use hand-crafted text-only problems as examples since it is not flexible to insert multiple images in one API call. The text-only setting is a unique approach under zero-shot where only the textual content of the problem is provided to the model, without any accompanying images. All the prompts used in our experiments, along with detailed descriptions of each setting, are available for public view and replication in our Github repository.
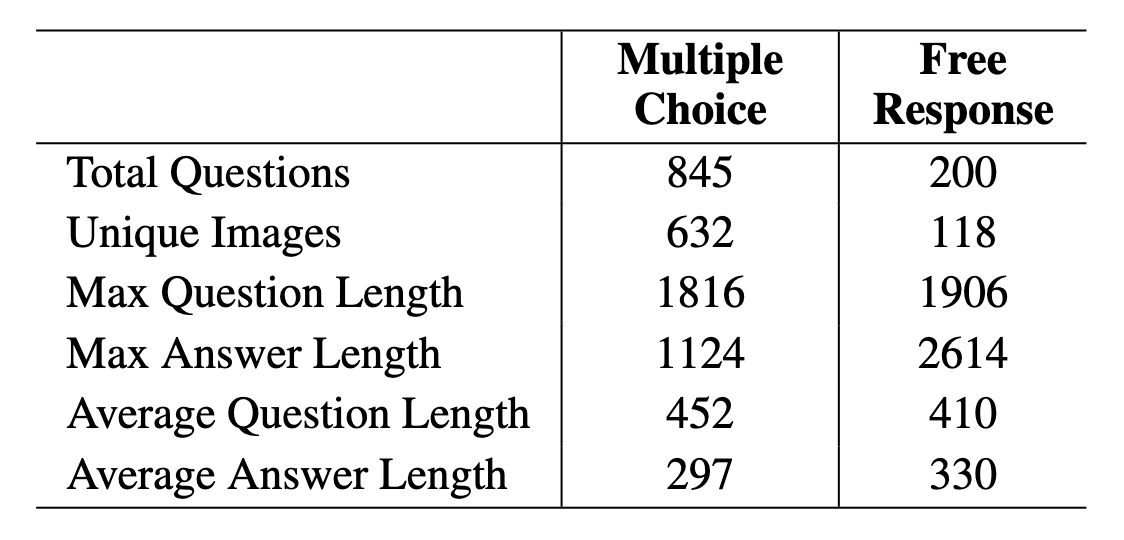
For the evaluation metric, we have chosen to use exact-match-based accuracy, which is consistent with several prior studies (Lu et al., 2023; Yue et al., 2023a)in this domain. This metric is particularly suitable for our benchmark as both the multiple-choice and free-response problems have definitive, singular correct answers. In the multiple-choice format, this involves selecting the correct option out of the presented choices. For the free-response format, it requires generating an accurate and precise answer, be it a numerical value, a yes/no response, or a specific term for fill-in-the-blank questions. Empirically we use rule-based answer exaction for multiple choice questions, and GPT4 as evaluators for free response questions.
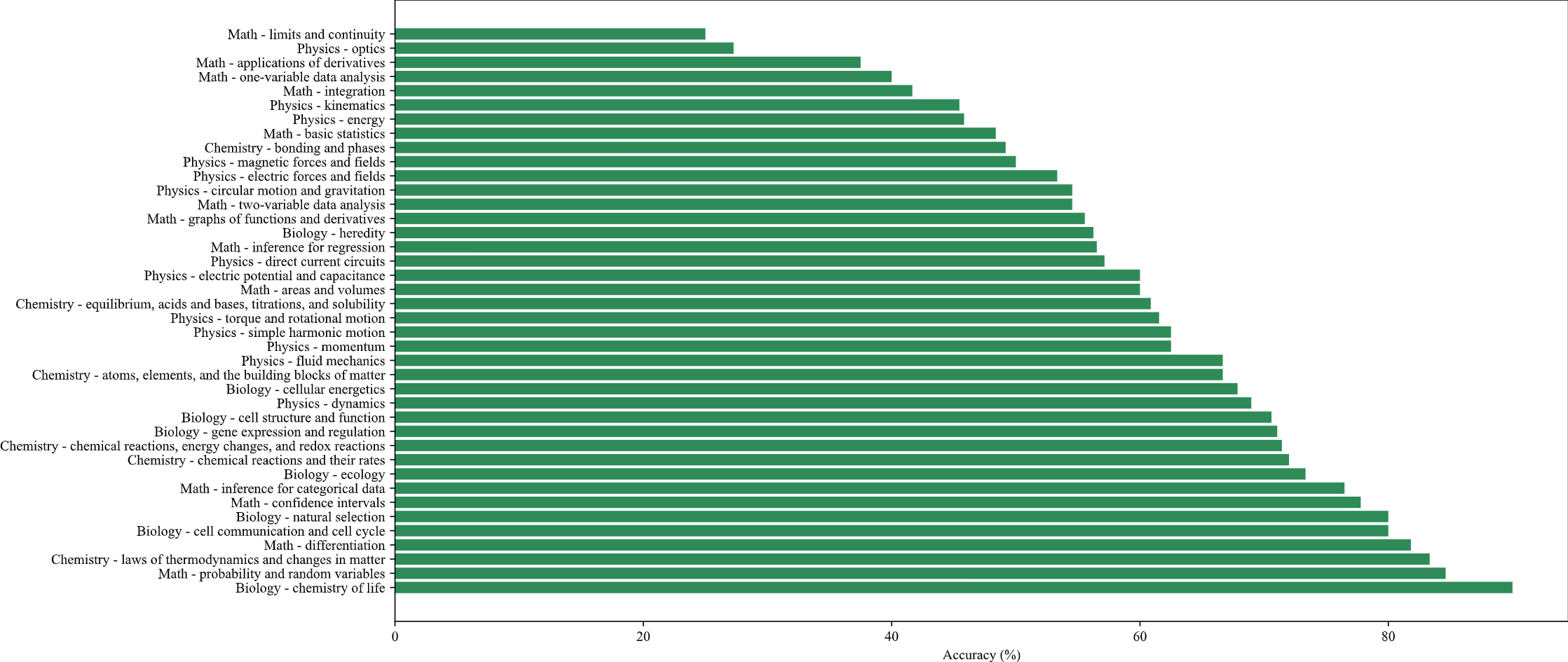
Accuracy distribution of GPT4-V on the knowledge points of SceMQA
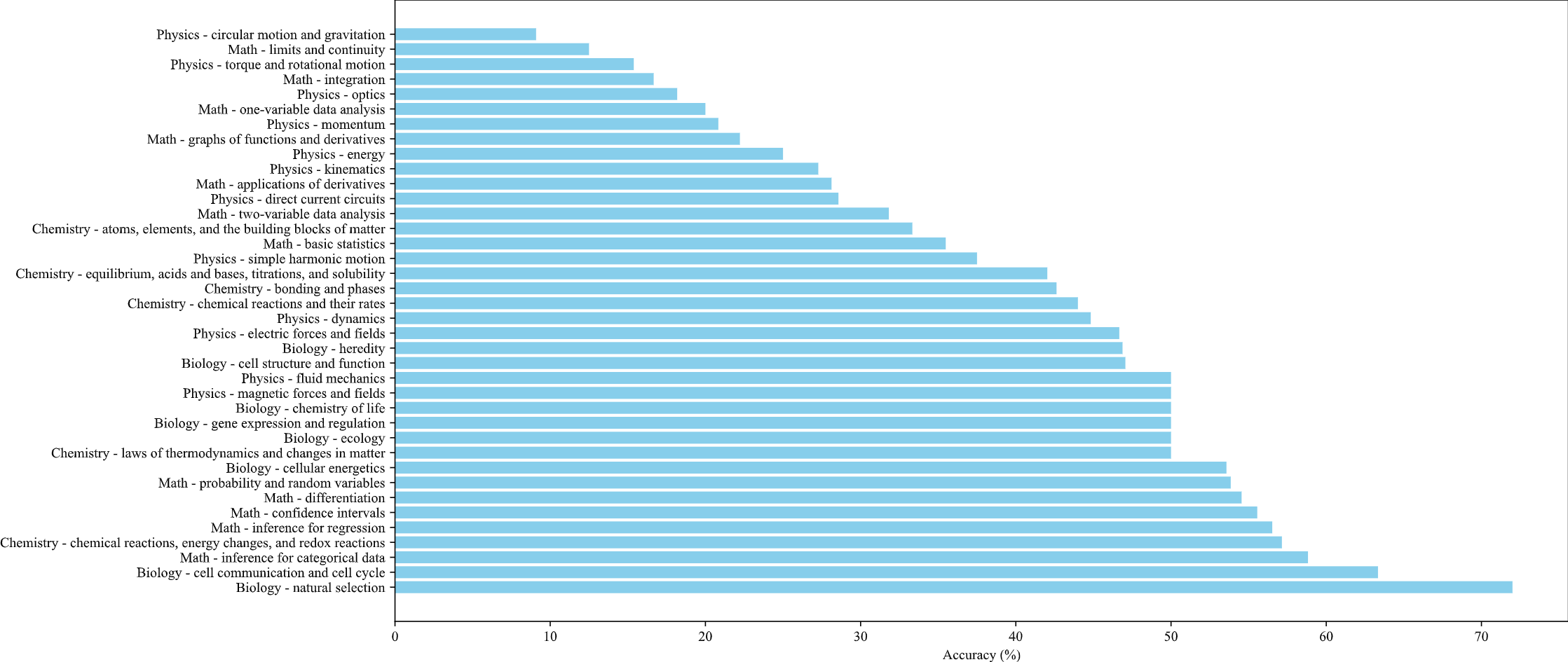
Accuracy distribution of Google Gemini on the knowledge points of SceMQA
| Open-sourced models | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Multiple Choice | Free Response | |||||||||
| Math | Physics | Chemistry | Biology | Overall | Math | Physics | Chemistry | Biology | Overall | ||
| InstructBLIP-7B | 16.98 | 21.86 | 20.30 | 22.75 | 20.48 | 6.00 | 6.00 | 0.00 | 38.00 | 12.50 | |
| InstructBLIP-13B | 19.34 | 19.53 | 17.33 | 28.91 | 21.31 | 8.00 | 12.00 | 4.00 | 30.00 | 13.50 | |
| MiniGPT4-7B | 18.87 | 20.93 | 25.25 | 22.75 | 21.90 | 4.00 | 0.00 | 2.00 | 20.00 | 6.50 | |
| MiniGPT4-13B | 27.39 | 20.93 | 27.23 | 35.55 | 27.74 | 2.00 | 4.00 | 8.00 | 14.00 | 7.00 | |
| LLaVA1.5-7B | 25.94 | 25.12 | 21.78 | 36.97 | 27.50 | 10.00 | 4.00 | 2.00 | 26.00 | 10.50 | |
| LLaVA1.5-13B | 31.13 | 28.37 | 26.24 | 38.86 | 31.19 | 12.00 | 4.00 | 4.00 | 32.00 | 13.00 | |
| Yi-VL-6B | 43.87 | 26.98 | 28.79 | 48.37 | 37.14 | 2.00 | 2.00 | 2.00 | 16.00 | 5.50 | |
| Deepseek-VL-Chat-7B | 24.53 | 21.86 | 26.26 | 34.42 | 26.79 | 6.00 | 10.00 | 6.00 | 34.00 | 14.00 | |
| InternLM-XComposer2-7B | 29.25 | 26.98 | 31.82 | 33.95 | 30.48 | 8.00 | 4.00 | 10.00 | 30.00 | 13.00 | |
| Qwen-VL-chat | 25.47 | 23.72 | 22.22 | 34.42 | 26.55 | 4.00 | 0.00 | 0.00 | 24.00 | 7.00 | |
| Closed-sourced models | |||||||||||
| Model | Setting | Multiple Choice | Free Response | ||||||||
| Math | Physics | Chemistry | Biology | Overall | Math | Physics | Chemistry | Biology | Overall | ||
| Google Bard | Text-only | 43.40 | 40.93 | 24.75 | 54.88 | 41.31 | - | - | - | - | - |
| Gemini Pro | Text-only | 21.70 | 19.53 | 32.51 | 46.51 | 30.06 | 8.00 | 6.00 | 8.00 | 38.00 | 15.00 |
| Few-shot | 36.79 | 30.23 | 37.44 | 48.84 | 38.34 | 18.00 | 12.00 | 12.00 | 36.00 | 19.50 | |
| Zero-shot | 37.26 | 30.70 | 42.36 | 54.42 | 41.18 | 20.00 | 12.00 | 18.00 | 36.00 | 21.50 | |
| GPT4-V | Text-only | 35.38 | 47.91 | 58.13 | 63.72 | 51.24 | 12.00 | 24.00 | 28.00 | 22.00 | 21.50 |
| Few-shot | 54.72 | 53.95 | 58.62 | 67.44 | 58.70 | 30.00 | 24.00 | 30.00 | 48.00 | 33.00 | |
| Zero-shot | 55.19 | 55.81 | 60.10 | 72.09 | 60.83 | 36.00 | 24.00 | 36.00 | 48.00 | 36.00 | |
Accuracy of examining GPT4-V and Gemini Pro across different settings on Multiple Choice and Free Response problems in SceMQA